Chapter 12 Quality Assurance of the pipeline
All the testing we have described so far is to do with the code, and ensuring that the code does what we expect it to, but because we have written an R package, it’s also very easy for us to institute tests for the consistency of the data at the time the data is loaded. We may also wish to employ defensive programming against potential errors and consider how we might want to flag these for the user and / or how our pipeline might recover from such errors.
12.1 Testing the input data
If our RAP were a sausage factory, the data would be the input meat. Given we do not own the input data nor are we responsible for its preparation we should plan for how we can protect our pipeline against a change in input data format or any anomalous data therein.
The list of tests that we might want to run is endless, and the scope of tests very much be dictated by the team which has the expert knowledge of the data. In the eesectors package we implemented two very simple checks, but these could very easily be expanded. The simplest of these is a simple test for outliers: since the data for the economic estimates is longitudinal, i.e. stretching back several years; we are able to look at the most recent values in comparison to the values from previous years. If the latest values lie within a threshold determined statistically from the other values then the data passes, if not a warning is raised.
These kinds of automated tests are repeated every time the data are loaded, reducing the burden of QA, and the scope for human error, freeing up statistician time for identifying more subtle data quality issues which might otherwise go unnoticed.
12.2 Murphy’s Law and errors in your pipeline
Paraphrasing from Advanced R by Hadley Wickham:
If something can go wrong, it will: the format of the spreadsheet you normally receive your raw data in changes, the server you’re talking to may be down, your Wi-Fi drops. Any such problem may stop a piece of your pipeline (code) from doing what it is intended to do. This is not a bug; the problem did not originate from within the code itself. However, if the pipeline downstream is dependent on this code acting as intended then you have a problem, you need to deal with the error somehow. Errors aren’t caused by bugs per se, but neglecting to handle an error appropriately is a bug.
12.3 Error handling
Not all problems are unexpected. For example, an input data file may be missing. We can often anticipate some of these likely problems by thinking about our users and how the code we might be implemented or misunderstood. If something goes wrong, we want the user to know about it. We can communicate to the user using a variety of conditions; messages, warnings and errors.
If we want to let the user know about something fairly inoccuous or keep them informed we can use the message() function. Sometimes we might want to draw the users attention to something that might be problematic without stopping the code from running, using warning(). If there’s no way for the code to execute then a fatal error may be preferred using stop().
As an example we look to code from the RAP eesectors package produced in collaboration with DCMS. Specifically, we look at a snippet of code from the year_sector_data function.
message('Checking x does not contain missing values...')
if (anyNA(x)) stop("x cannot contain any missing values")
message('Checking for the correct number of rows...')
if (nrow(x) != length(unique(x$sector)) * length(unique(x$year))) {
warning("x does not appear to be well formed. nrow(x) should equal
length(unique(x$sector)) * length(unique(x$year)). Check the of x.")
}
message('...passed')We’ll work our way through the code above, step by step. The first line informs the user of the quality assurance that is being automatically conducted, i.e. that no data is missing (NA). The second line uses the logical if statement to assess this on x and if it were true, we use stop to produce a fatal error with a descriptive message, as below.
x <- c("culture", "sport", NA)
message('Checking x does not contain missing values...')## Checking x does not contain missing values... if (anyNA(x)) stop("x cannot contain any missing values")## Error in eval(expr, envir, enclos): x cannot contain any missing valuesThe third line checks that the data has data for each sector for each year (indirectly). If not it throws up a warning, as this could be for a valid reason (e.g. a change of name of a factor level), but it’s better to let the user know rather than let it quietly pass. Thus all the expert domain knowledge can be incorporated into the code through condition handling, providing transparent quality assurance.
These informative messages are useful but when used in conjuction with tryCatch, we can implement our own custom responses to a message, warning or error (this is explained in the relevant Advanced R Chapter). We demonstrate a simplified example from the eesectors package where an informative message is provided. This is achieved by wrapping the main body of the function within the tryCatch function.
# Define as a method
figure3.1 <- function(x, ...) {
out <- tryCatch(
expr = {
p <- plot(x, y)
return(p)
},
warning = function() {
w <- warnings()
warning('Warning produced running figure3.1():', w)
},
error = function(e) {
stop('Error produced running figure3.1():', e)
},
finally = {}
)
}The body of a tryCatch() must be a single expression; using { we combine several expressions into a single form. This a simple addition to our function but it’s powerful in that it provides the user with more information for anticipated problems.
By wrapping the code in the tryCatch function we ensure that it gets evaluated, whereas normally an error would cause the evaluation of the code to stop. Instead we get the error and the evaluation of the next line of code.
try(print(this_object_does_not_exist)); print("What happens if this is not wrapped in try?")## [1] "What happens if this is not wrapped in try?"12.4 Error logging
We are increasingly using R and software packages like our RAP in “operational” settings that require robust error handling and logging. In this section we describe a quick-and-dirty way to get python style multi-level log files by wrapping the futile.logger package inspired by this blog post.
12.4.1 Pipeline pitfalls
Our real world scenario involves an R package that processes raw data (typically from a spreadsheet or SQL table) that is updated periodically. The raw data can come from various different sources, set up by different agencies and usually manually procured or copy and pasted together prioritising human readability over machine readability.
Data could be missing or in a different layout from that which we are use to, for a variety of reasons, before it even gets to us. And then our R functions within our package may extract this data and perform various checks on it. From there a user (analyst / statistician) may put together a statistical report using Rmarkdown ultimately resulting in a html document. This pipeline has lots of steps and potential to encounter problems throughout.
As we develop our RAP for our intended bespoke problem and start to use it in an operational setting, we must ensure that in this chaotic environment we protect ourselves against things going wrong without our realising. One of the methods for working with chaotic situations in operational software is to have lots and Lots and LOTS of logging.
We take our inspirration from Python, which has the brilliant “logging” module that allows us to quickly set up separate output files for log statements at different levels. This is important as we have different users who may have different needs from the log files. For example, the data scientist / analyst who did the programming for the RAP package may wish to debug the code on logging an error whereas a statistician may prefer to be notified only when an ERROR or something FATAL occurred.
12.4.2 Error logging using futile.logger
Fortunately there’s a package available on CRAN that makes this process easy in R called futile.logger. There are a few concepts that it’s helpful to be familiar with before proceeding which are introduced in this blog post by the package author.
One approach is to replace tryCatch with the ftry function with the finally. This function integrates futile.logger with the error and warning system so problems can be caught both in the standard R warning system, while also being emitted via futile.logger.
We think about how to adapt our earlier code to this function. The primary use case for futile.logger is to write out log messages. There are log writers associated with all the predefined log levels: TRACE, DEBUG, INFO, WARN, ERROR, FATAL. Log messages will only be written if the log level is equal to or more urgent than the current threshold. By default the ROOT logger is set to INFO but this can be adjusted by the user facilitating customisation of the error logging to meet the needs of the current user (by using the flog.threshold function).
We demonstrate this hierarchy below by evaluating this code.
# library(futile.logger)
futile.logger::flog.debug("This won't print")
futile.logger::flog.info("But this %s", 'will') ## INFO [2019-03-01 14:51:32] But this willfutile.logger::flog.warn("As will %s", 'this')## WARN [2019-03-01 14:51:32] As will thisx <- c("culture", "sport", NA)
message('Checking x does not contain missing values...')
if (anyNA(x)) stop("x cannot contain any missing values")We start by re-writing the above code using the futile.logger high level interface. As the default setting is at the INFO log level we can use flog.trace to hide most of the checks and messages from a typical user.
# Data from raw has an error
x <- c("culture", "sport", NA)
### Non-urgent log level
futile.logger::flog.trace("Checking x does not contain missing values...")
### Urgent log level, use capture to print out data structure
if (anyNA(x))
{
futile.logger::flog.error("x cannot contain any missing values.",
x, capture = TRUE)
}## ERROR [2019-03-01 14:51:33] x cannot contain any missing values.
##
## [1] "culture" "sport" NAfutile.logger::flog.info("Finished checks.")## INFO [2019-03-01 14:51:33] Finished checks.The above example can help the user identify where the pipeline is going wrong by logging the error and capturing the object x where the data is missing. This allows us to more quickly track down what’s going wrong.
12.4.3 Logging to file
At the moment we default to writing our log to the console. We could write to a file if interested using the appender family of functions.
# Print log messages to the console
futile.logger::appender.console()
# Write log messages to a file
futile.logger::appender.file("rap_companion.log")
# Write log messages to console and a file
futile.logger::appender.tee("rap_companion.log")12.5 Proof calculation
Regardless of how the results are published or the methodology used, the results need to be checked for correctness. Here we explore how we can use statistics to help us validate the correctness of results in a RAP.
The scientific method of choice to address validity is peer review. This can go as far as having the reviewer implement the analysis as a completely separate and independent process in order to check that results agree. Such a co-pilot approach fits nicely to the fact that real-life statistical analysis rarely is a one-person activity anymore.
In practice, there might neither be a need nor the resources to rebuild entire analyses, but critical parts need to be double-checked. There a variety of appraoches you could try that will suit different problems.
- Pair programming is one technique from the agile programming world to accomodate this.
- Single programmers coding independently and then comparing results.
- Peer review of code and tests throughout the development process using Github.
In our RAP projects to date we have opted for the third choice, as often our aim is to build programming capability as well as correct and reproducible results through code. We also use unit tests to check the critical areas of code by providing an expectation. However, unit tests are more useful for detecting errors with a code during development, as they are a manifestation of our expert domain knowledge. They are only as comprehensive as the work invested in writing them, conversely one does not need infinite tests.
If you are interested in taking these ideas further and using statistics to help you estimate the number of wrong results in your report as part of your QA process, then read this blog.
12.6 When should one stop testing software?
Imagine that a team of developers of a new RAP R package needs to structure a test plan before the publication of their report. There is an (unknown) number of bugs in the package. The team starts their testing at time zero and subsequently find an increasing number of bugs as the test period passes by. The figure below shows such a testing process mimicking the example of Dalal and Mallows (1988) from the testing of a large software system at a telecommunications research company.
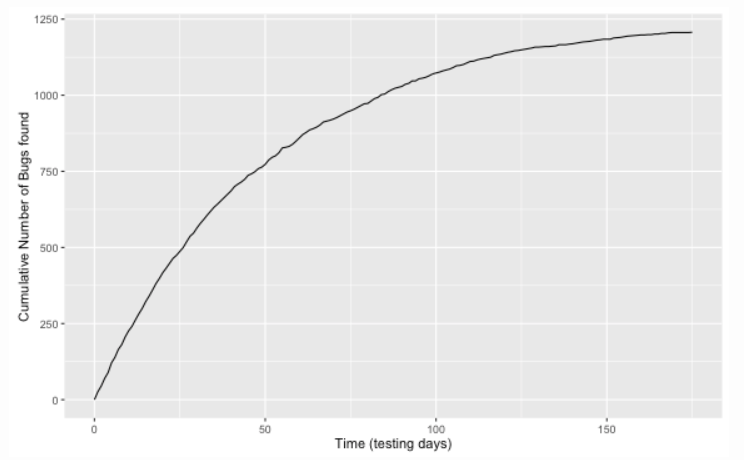
We see that the number of bugs appears to level off. The question is now how long should we continue testing before releasing? For a discussion of this problem, see this blog, from which we have paraphrased.